

Table of Contents
Introduction to What is a Data Pipeline?
What is a Data Pipeline? As of 2021, we are all aware of the vast amounts of data that is churned by the minute. Take the example of the popular online retail platform, Amazon. Every minute there are about 4000 items being sold only in the US. Imagine the data that needs to be processed and stored – add items to cart, procure bill and receipt, calls to payment APIs etc. All this requires a steady and uninterrupted flow of data in transactions, with no bottlenecks occurring due to processing.
This is made possible through data pipelining. Data pipelining is a set of actions that takes in raw data from sources and moves the data for either storage or analysis. Just like oil and water require physical pipelines to be transported in gallons, data pipelining is an efficient way of extracting, transforming and moving gigabytes of data. It is basically what enables the smooth flow of information.
Ever noticed that when you’re buying, say that watch on Amazon, you are hardly faced by any failures. This is because data pipelines these days are extremely sturdy, with built-in filters and the ability to provide resiliency against such faulty transactions. Data engineers are behind the development and maintenance of data pipelines. Let us read on to learn more about the need and idealogy behind data pipelining.
Why Do We Need Data Pipelines?
- Allows flexibility
The world of data is constantly evolving and transforming. Rigid practices like ETL (Extract, Transform, Load) can no longer be implemented by companies like Facebook, Amazon, Google for storage and analysis of data as it becomes unyielding in the future run. A data pipeline allows continuous data and adaptable schemas for storage. They can also be easily routed to visualization tools like Salesforce for analysis.
- Allows the transformation of vast amounts of data
Data pipeline does not only constitute the transport of data from an origin to a destination. Moder data pipelines are built to enable processes like extraction, transformation, validation and integration as well. It also can process a myriad of parallel information streams.
- Enable quick data analysis for business insights
Data pipelines serve as a reliable platform for the management and usage of data. It empowers enterprises to analyse data with integration to visualization tools to deliver actionable insights.
- Allows data consistency
Since data is collected from diverse sources, there is a need to format the data to allow coherence. Supposedly if the data is in real-time, such as time-series data, it further compounds the discrepancy dilemma. Data pipelining is an efficient means to handle growing data load and maintain data accuracy. It also ensures that no data is lost.
- Increases efficiency
Data pipelines allow for the migration and transformation of data with exceeding performance capabilities. The strong infrastructure also allows for great data quality by weeding out erroneous data transactions and disallowing data redundancy.
Ways to implement data pipeline
| In-house data pipeline | Cloud-based data pipeline |
| Construction, maintenance and deployment of the data pipeline is within the organisation | Using a cloud-based tool, a business doesn’t require any hardware. They access a provider’s cloud service. |
| For each kind of data source, a different technology needs to be implemented. Making this approach bulky | Cloud-based services are more flexible |
| Offers the advantage of having complete control of data and its utilization | Offers the advantage of easier scalability and speed optimization. |
Widget not in any sidebars
Data Pipeline Architecture
As you have understood by now, data pipelining isn’t only about the flow of data from a source to its destination. It is a complex system that involves capturing, management and transforming data. We can break it down into the following key components –
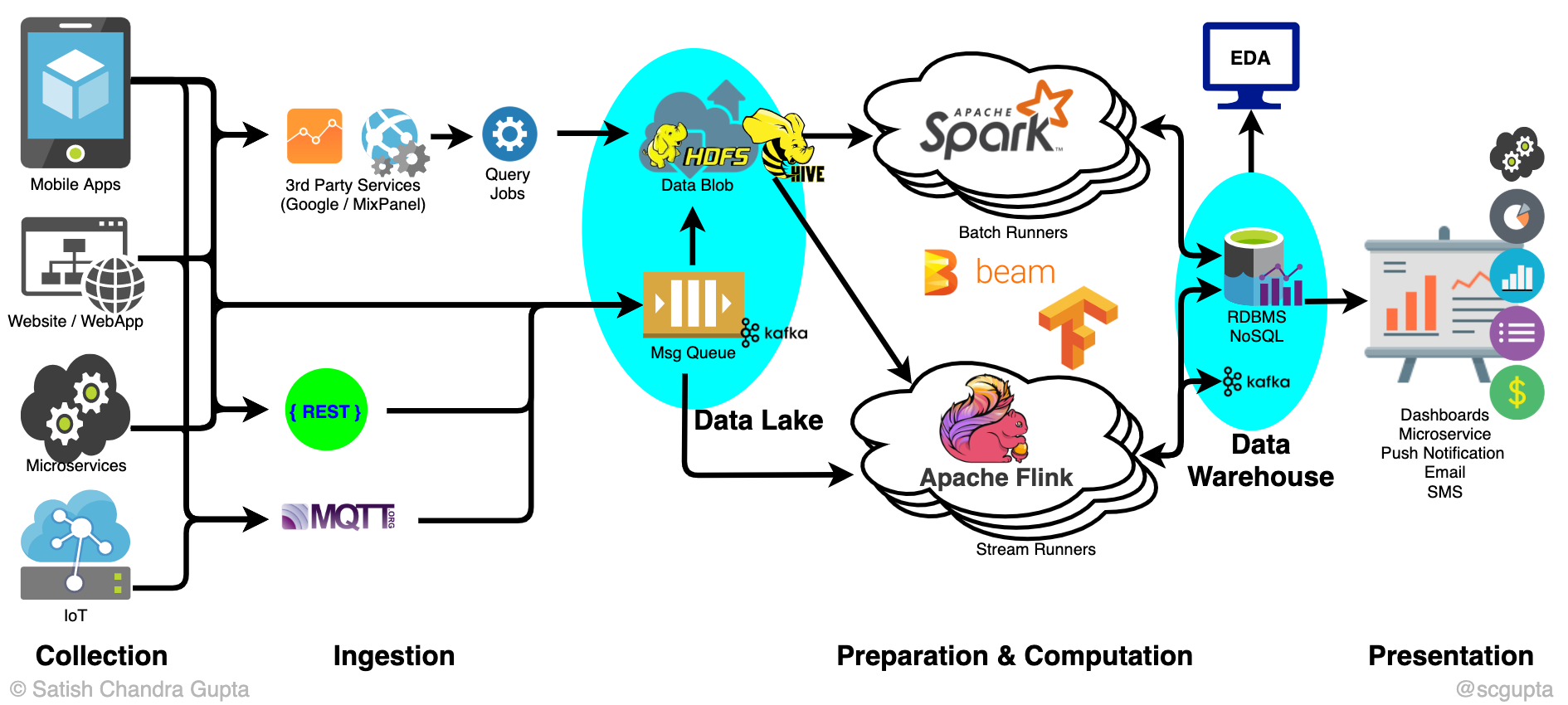
- Source
Data can enter a pipeline through multiple data sources (transaction processing application, IoT sensors, social media, payment gateway APIs etc.) as well as data servers. Such sources can be on the Cloud, relational databases, NoSQL and Hadoop servers.
- Storage
Even during the process of conversion of data, data needs to be stored periodically in different stages of the pipeline. The data storage used is based on the purpose they serve. Sometimes companies need to deal with huge volumes and other times they are concerned with speed. We have discussed some technologies used for storage purposes in the latter part of this article.
- Transformation
Raw data and especially ones from variable sources needs to be preprocessed in a way to make it useful for businesses. Transformation tools are essential in:
– Standardizing the data
– Sorting data and removing redundancies
– Validation and filtering of data
Transformation is necessary to serve the purpose of easier analysis of data to generate beneficial insights for corporations.
- Workflow
A workflow in a pipeline is designed to better enable the sequencing and flow of data. Managing the workflow also aids in handling the interdependency of modules.
- Destination
All the processed and transformed data is transferred to this final stage. The destination can be optimised based on the enterprise’s utilisation of data. It can be moved to storage for future use or it can be directly streamed to data visualisation tools for analysis.
Data pipeline technologies
In order to create a data pipeline in real-time, there are several tools available today for collecting, analyzing and storing several million streams of data. Data pipeline tools have been made easily available and come in many forms, but they all serve the same purpose of extraction, loading and transformation.
Some popular tools used in building pipelines are –
| Tool | Purpose and benefits |
| Apache Spark | Spark is an excellent tool that has the capability to deal with real-time data streaming. Moreover, it is an open-source technology that supports Java, Python and Scala. Spark offers high performance and speed. |
| Hadoop | Having made its presence known in the big data world, Hadoop can handle and compute huge volumes of data with relative ease. It works with MapReduce that processes the incoming data and Yarn that divides it into streams. It is scalable on a wide array of servers and offers fault tolerance. |
| Kafka | In any data pipelining architecture, Kafka is what enables the integration and combination of data. Using ksqlDB, filtering and querying of data are also made easy. In addition to real-time data, Kafka also allows the use of REST services and JDBC. One of the more salient features of Kafka is it provides zero data loss. |
| Amazon Web Service (AWS) | AWS is an extremely popular technology amongst data engineers. Within its toolbox, it contains implementations of data mining, storage and processing. Many businesses opt for using AWS as it is viable and highly scalable to serve the functionality of real-time data processing. |
Use case of Data Pipeline – Payment Gateways
Payment gateways act as a central point of contact between the customer, the bank and the online retail platform. The steps involved in the back-end data pipeline are
- Order is placed by the customer
The customer submits personal details and payment data to facilitate the transaction. The data pipelines built should ensure that all these details are secure and is generally encrypted and passed only under HTTPS.
- Payment is authenticated
Next, the payment is verified by making the customer enter specific pieces of information like CVV and OTP (One Time Password). OTPs have been revolutionary in order to ensure security and to decline transactions if deemed fraudulent. APIs are in place to validate the transaction, check balance and generate OTP all within a matter of a few seconds!
- Payment is approved and order placed
Once the payment is approved by the banking merchant, the order is confirmed by the retailing platform. An invoice is generated and the customer is immediately able to view his order history.
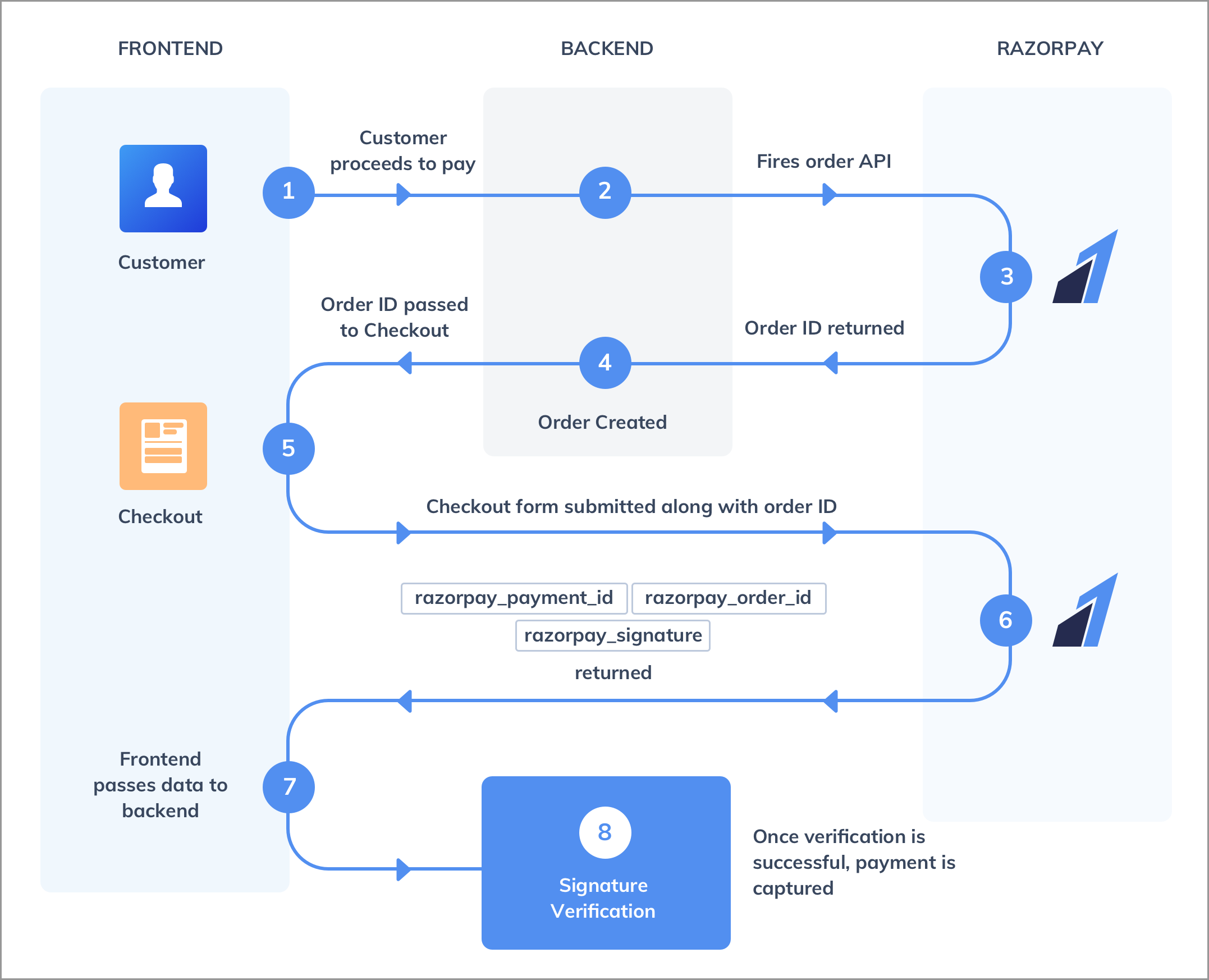
A payment hub service also has to ensure that it maintains –
- Authentication
- Security
- Speed
Data pipelines help achieve this.
Summary
- A data pipeline provides enterprises access to reliable and well-structured datasets for analytics.
- Data pipelines automate the movement and transformation of data.
- By combining data from disparate sources into one common destination, data pipelines ensure quick data analysis for insights.
- Data quality and consistency are ensured within companies that use data pipelines.
Widget not in any sidebars


{kind=link}