Language Translation Using Deep Learning: A Complete Guide
Language Translation Using Deep Learning
Language translation is one of the most impactful applications of Artificial Intelligence and Natural Language Processing (NLP). From translating websites and documents to powering tools like Google Translate and multilingual chatbots, Deep Learning has revolutionized the way machines understand and translate human languages.
Traditional translation systems relied heavily on manually created rules and dictionaries. However, modern Deep Learning models can learn language patterns automatically and provide highly accurate translations across hundreds of languages.
In this article, you'll learn how Language Translation works using Deep Learning, the technologies behind it, real-world applications, challenges, and future opportunities in AI.
What is Language Translation?
Language Translation is the process of converting text or speech from one language into another while preserving its meaning and context.
Example:
English
Artificial Intelligence is transforming the world.
Hindi
कृत्रिम बुद्धिमत्ता दुनिया को बदल रही है।
The goal is to generate accurate and context-aware translations rather than simply replacing words.
What is Deep Learning?
Deep Learning is a subset of Machine Learning that uses Artificial Neural Networks with multiple layers to learn complex patterns from large amounts of data.
Deep Learning powers various AI applications such as:
Image Recognition
Speech Recognition
Chatbots
Recommendation Systems
Language Translation
Generative AI
Its ability to understand context makes it highly effective for translation tasks.
Why Traditional Translation Systems Were Limited
Earlier Machine Translation systems used:
Rule-Based Translation
Relied on predefined grammar and linguistic rules.
Challenges:
Difficult to scale
Required extensive manual effort
Limited language coverage
Statistical Machine Translation (SMT)
Used probabilities and statistical patterns.
Challenges:
Struggled with context
Produced unnatural translations
Limited understanding of sentence structure
These limitations led to the development of Neural Machine Translation (NMT).
What is Neural Machine Translation (NMT)?
Neural Machine Translation is a Deep Learning approach that uses neural networks to translate text from one language to another.
Unlike traditional systems, NMT translates entire sentences while considering context and meaning.
Benefits include:
Better fluency
Improved accuracy
Context-aware translation
Support for multiple languages
NMT is now the industry standard for modern translation systems.
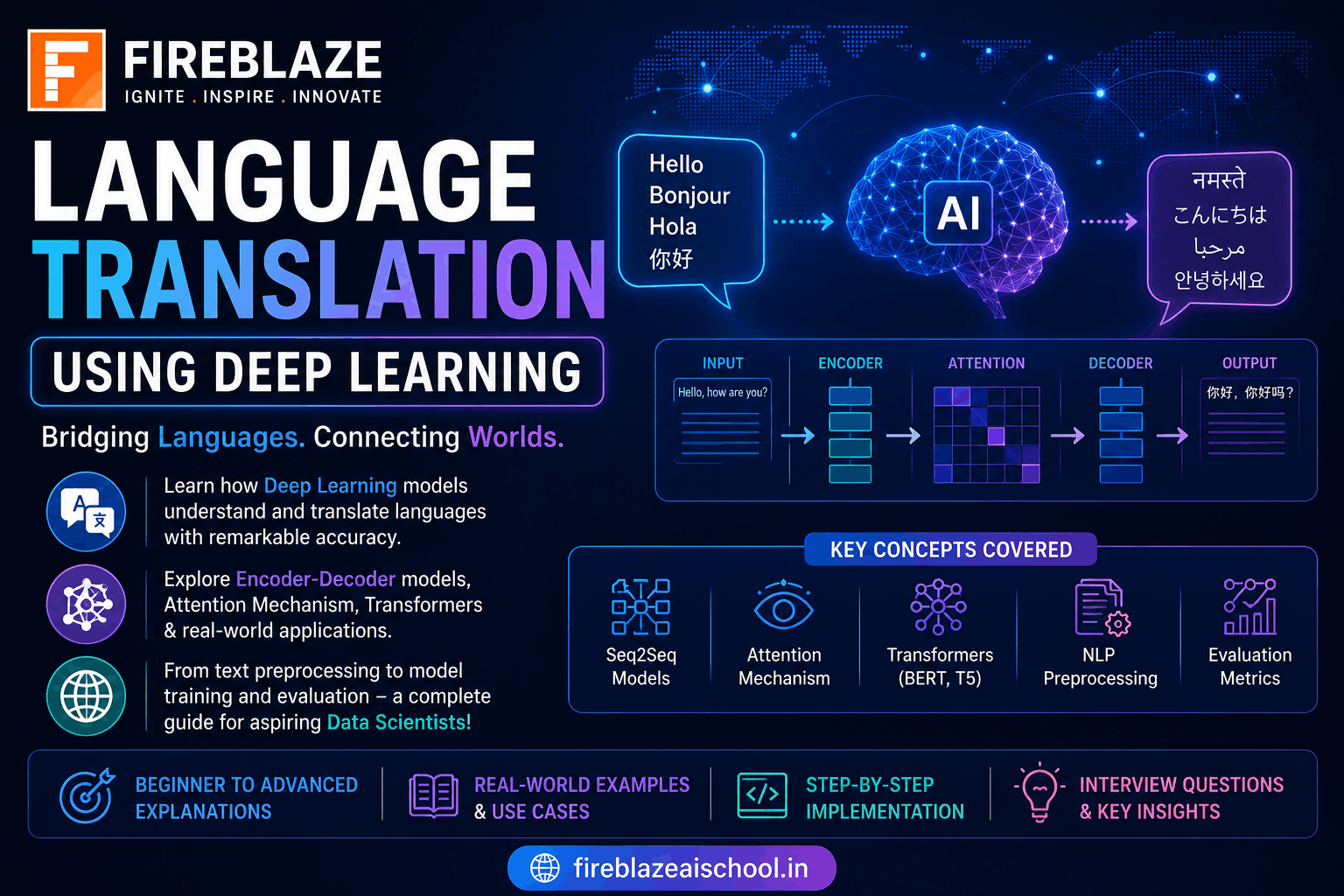
How Deep Learning Language Translation Works
The translation process typically follows these steps:
Step 1: Input Text
Example:
How are you today?
Step 2: Text Processing
The sentence is converted into tokens.
Example:
["How", "are", "you", "today"]
Step 3: Encoding
The encoder converts words into numerical representations called embeddings.
These embeddings capture semantic meaning.
Step 4: Context Understanding
The model learns relationships between words and sentence structure.
Example:
Understanding that:
bank
may refer to:
Financial institution
River bank
depending on context.
Step 5: Decoding
The decoder generates the translated sentence word by word.
Output:
आज आप कैसे हैं?
Seq2Seq Model in Language Translation
One of the earliest Deep Learning architectures for translation was the Sequence-to-Sequence (Seq2Seq) model.
Components:
Encoder
Reads and understands the input sentence.
Decoder
Generates the translated sentence.
Example
Input:
I love Artificial Intelligence.
Output:
मुझे कृत्रिम बुद्धिमत्ता पसंद है।
Seq2Seq models laid the foundation for modern translation systems.
Attention Mechanism
A major breakthrough in language translation was the Attention Mechanism.
Instead of processing entire sentences as a single representation, attention allows models to focus on relevant words during translation.
Benefits:
Better context understanding
Improved translation accuracy
Handling long sentences effectively
Attention significantly improved Neural Machine Translation performance.
Transformer Models
The Transformer architecture revolutionized language translation.
Unlike RNNs and LSTMs, Transformers process words in parallel and use self-attention mechanisms.
Advantages:
Faster training
Better scalability
Improved contextual understanding
Higher translation quality
Popular Transformer-based models include:
BERT
GPT
T5
mBART
MarianMT
Most modern translation systems use Transformer-based architectures.
Popular Deep Learning Models for Translation
RNN (Recurrent Neural Networks)
Suitable for sequential data but struggled with long-term dependencies.
LSTM (Long Short-Term Memory)
Improved handling of long sentences and context.
GRU (Gated Recurrent Unit)
Faster alternative to LSTMs.
Transformers
Current industry standard for translation and NLP tasks.
Language Translation Using Python
Developers can build translation systems using popular libraries.
Install Transformers
pip install transformers
Example Using Hugging Face
from transformers import pipeline
translator = pipeline(
"translation",
model="Helsinki-NLP/opus-mt-en-hi"
)
result = translator(
"Artificial Intelligence is changing the future."
)
print(result)
Output:
कृत्रिम बुद्धिमत्ता भविष्य को बदल रही है।
Real-World Applications of Language Translation
Google Translate
Supports hundreds of languages using Deep Learning.
Multilingual Chatbots
Customer support systems communicate with users in different languages.
International Business
Organizations translate documents, websites, and communications.
Healthcare
Medical documents and patient information can be translated accurately.
Education
Learning materials become accessible to global audiences.
Travel Industry
Travel platforms provide multilingual support for users worldwide.
Challenges in Language Translation
Despite major advancements, challenges still exist.
Ambiguity
Words can have multiple meanings.
Example:
Bat
Could mean:
Animal
Sports equipment
Idioms and Expressions
Example:
Break a leg
Literal translation may not preserve intended meaning.
Cultural Context
Languages often contain cultural references that are difficult to translate directly.
Low-Resource Languages
Many languages have limited training data available.
Future of Language Translation
The future of AI-powered translation includes:
Real-Time Translation
Speech-to-Speech Translation
Multimodal Translation
AI-Powered Interpreters
Cross-Language Search Engines
Large Language Models (LLMs) are further improving translation quality and contextual understanding.
Career Opportunities in NLP and Translation AI
Professionals skilled in NLP and Deep Learning can pursue careers such as:
NLP Engineer
Machine Learning Engineer
AI Engineer
Data Scientist
Computational Linguist
Research Scientist
As multilingual AI systems continue to grow, demand for NLP professionals is expected to increase significantly.
Why Learn Language Translation in AI?
Language Translation combines multiple advanced AI concepts:
Natural Language Processing
Deep Learning
Neural Networks
Transformer Models
Generative AI
Learning these concepts helps build strong foundations for careers in Artificial Intelligence and Machine Learning.
Final Thoughts
Language Translation using Deep Learning has transformed global communication. Modern Neural Machine Translation systems powered by Transformers and Attention Mechanisms can generate highly accurate and context-aware translations across multiple languages.
As AI continues to evolve, language translation systems will become even more intelligent, enabling seamless communication between people, businesses, and technologies worldwide. Understanding these technologies is an excellent step toward mastering Natural Language Processing and building a successful career in Artificial Intelligence.
Suggested Internal Links
What is Natural Language Processing (NLP)
Sentence Segmentation Using NLP
Transformer Models Explained
Machine Learning vs Deep Learning
Artificial Intelligence Course
Data Science Career Roadmap
Focus Keyword
Language Translation Using Deep Learning
Secondary Keywords
Neural Machine Translation
Deep Learning for Language Translation
NLP Translation Models
Transformer Translation Models
Language Translation in AI
Natural Language Processing Applications