

Table of Contents
Introduction To K-nearest neighbors Algorithm
Supervised machine learning algorithms include this K-nearest neighbors (KNN) algorithm. It uses all of the data for training while classifying a new data point or instance, It searches through the entire training dataset for k-neighbors similar instances, and the data with the most occurrence instance is finally returned as the prediction.
It doesn’t assume anything about the underlying data for this reason KNN is known as a non-parametric learning algorithm. It classifies the new data point with the help of using all training data. This means it captures the information from all training data and classifies the new data point as (0 / 1) based on similarity.
Working of K-nearest neighbors Algorithm
Predictions in KNN are made for a new instance (x) by searching through the all training data for the K most similar cases (neighbors) and gives the output variable for those K cases. In a classification problem, it is the mode value that means the most common class value.
Step 1:- Working is that simply calculates the distance of a new data point to all other training data points. The distance can be of any type e.g: Manhattan or Euclidean.
Step 2:- It then selects the K-nearest data points, where K can be any integer. e.g: (1,2,3,…)
Step 3:- It assigns the data point to the class to which the majority( mode value ) of the K data points belong. e.g: classifies the new data point 4 output five are in class one so the new data point assign as class one
Example:-
Suppose we have a dataset with two classes Red and green which when plotted is look like as below.
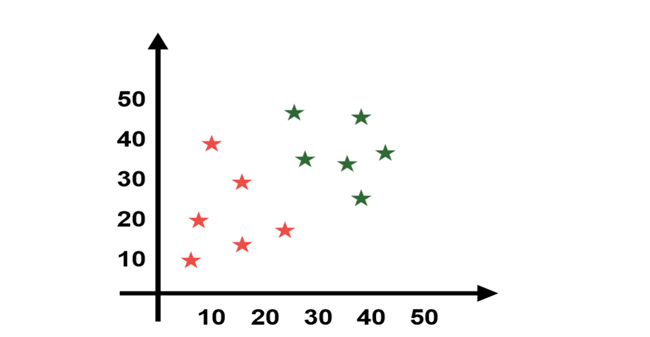
Problem statement is classified new data instance( X ) into Red or Green class which input are X = 25 and Y = 25
Consider in below graph X is a new data instance point.
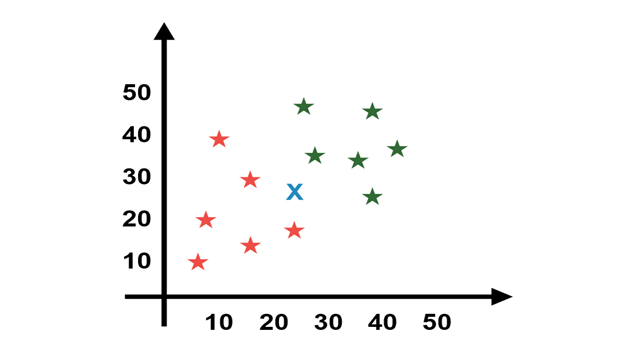
Now the working of KNN is starting to calculate the distance from new data instance to each and every training data instance point, and in supposing the value of k = 3 then find the 3 nearest points with least
Widget not in any sidebars
distance to point X. The three nearest points have been encircled.
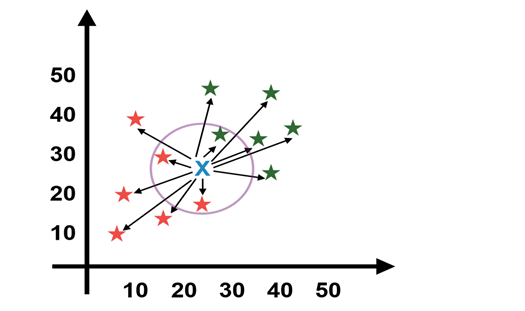
The final step of the KNN algorithm is to assign a new point to the class to which the majority of the three nearest points belong. According to the circle two of the three nearest points belong to the class Red on class while one belongs to the Green class. Therefore the new data point will be classified as Red class.
Widget not in any sidebars
Formula for distance measure:-
To calculate distance from numerical continuous data that time we used generally Euclidean Distance, Manhattan Distance, and Minkowski Distance used anyone out of it.

At the time of categorical variables used hamming distance It also brings up the issue of standardization of the numerical variables between 0 and 1 when data contain is a mixture of quantitative( numerical ) and qualitative (categorical ) variables in the data.

Following real word problem statement solve by using the K nearest neighbor(KNN).
Suppose we have myntra e-commerce customer data which contain height, weight and T-shirt size of some customers
The problem statement is to predict the T-shirt size of a new customer given only height and weight information. Given the data.
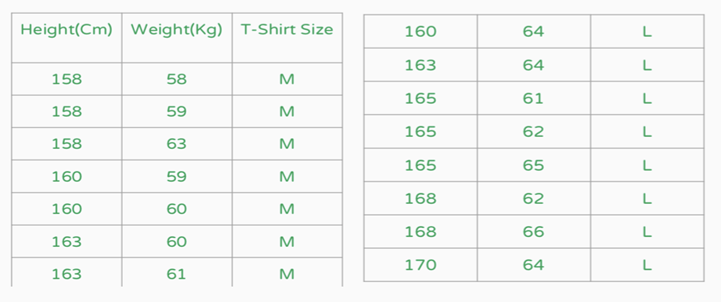
New Customer Anurag has Height = 161 Cm and weight = 61 Kg.
Nex step is to calculate distance from the training data point. So we used euclidean Distance to calculate distance from new data point to training data point, calculate first observation, and new observation data distance.
Example:-
Euclidean Distance :
d(x,y) = √ (161-158)2 + (61 – 58)2
d(x,y) = sqrt( 32+32) = sqrt(9+9) = sqrt(18) = 4.25 <- Distance of from first observaltion.
All Euclidean Distances between all observations and new observations.
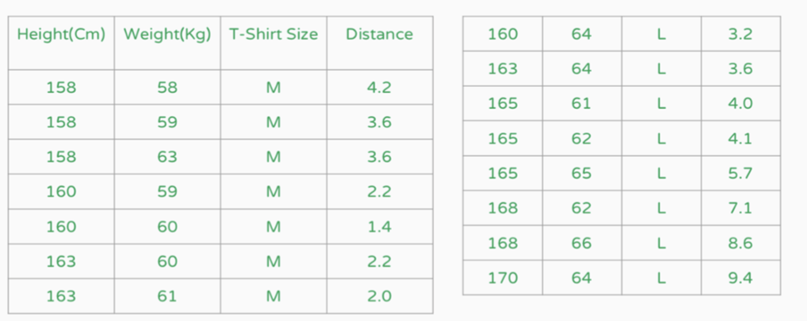
Now process is passing the k value and identify the mode of the data point to classify the point.
Take K = 3 and identify the 3 nearest distance point.
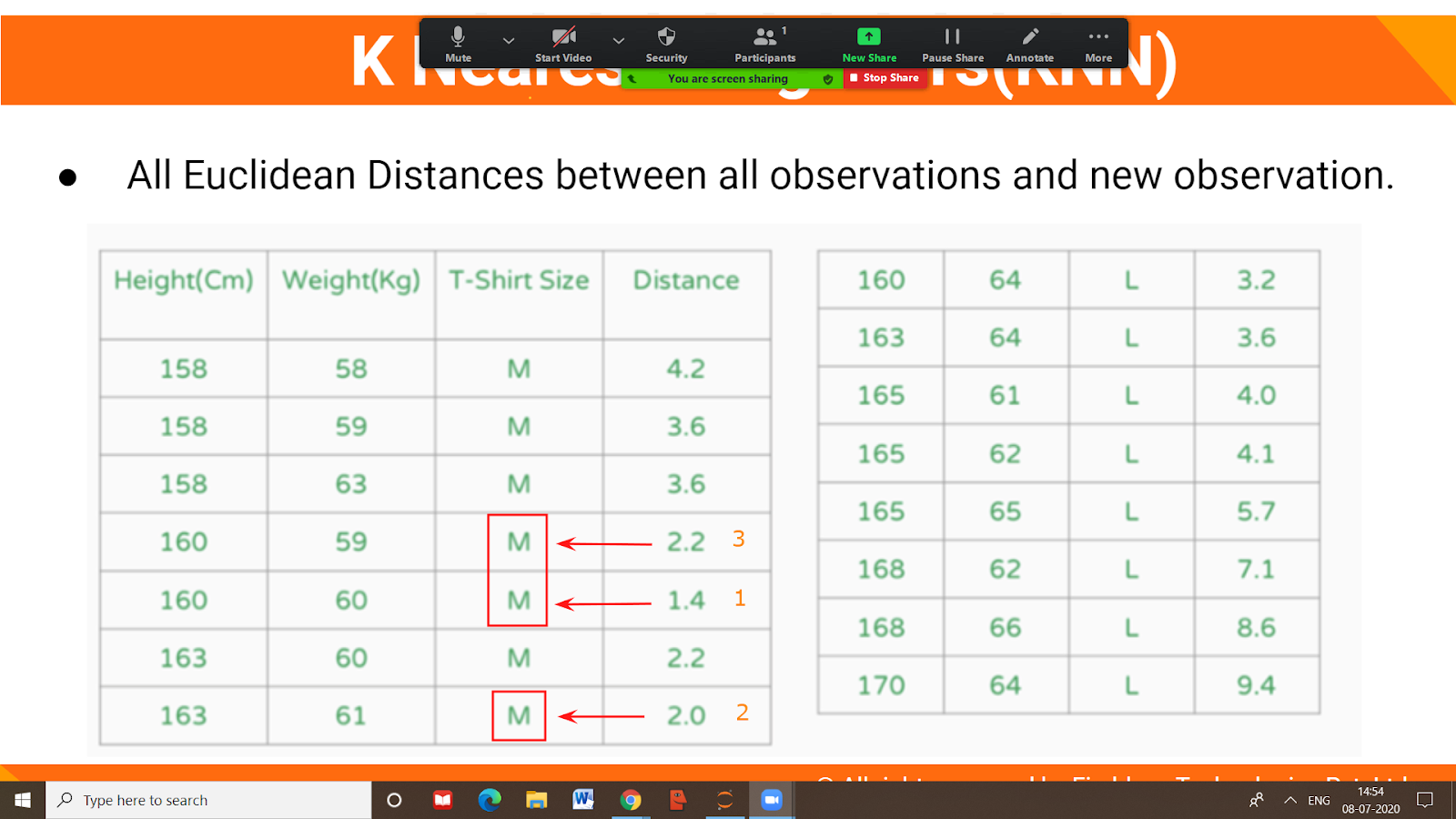
Nearest neighbor would be – 1.4, 2.0, 2.2 This would lie inside the circle.
Hence your neighbors are contained T-shirt size – M, M, M
Therefore, Our model will classify Anurag’s T-Shirt size to be M.
Pros of KNN
- It is extremely easy to implement.
- As said earlier, it is a lazy learning algorithm and therefore requires no training prior to making real-time predictions. This makes the KNN algorithm much faster than other algorithms to implement that requires training e.g SVM, linear regression, etc.
- Only two parameters required to implement KNN i.e. To calculate distance pass distance function (e.g. Euclidean or Manhattan etc.) and k neighbor value ( K )
Cons of KNN
- It becomes difficult for the algorithm to calculate the distance in each dimension so the doesn’t work well with high dimensional data
- In large datasets, the cost of calculating distance between the new points and each existing point becomes higher so The KNN algorithm has a high prediction cost for large datasets
- It is difficult to find the distance between dimensions with categorical features so the algorithm doesn’t work well with categorical features
Note:- Since the range of values of raw data varies widely, in some machine learning algorithms, objective functions will not work properly without normalization.
For example, suppose you want to calculate the distance between two points by the euclidean distance. Out of this two feature one of the feature is a wide range (e.g. Salary column contain range between 10K to 80K), the distance will be governed by this particular feature. Therefore, the range of all features should be insane range so that each feature contributes approximately proportionately to the final distance.
Conclusion
IN this blog you will get a better understanding of K-nearest neighbors Algorithm it’s working and parameters to classify the data, and their implementation.







 algorithm. KNN is known as a non-parametric learning algorithm.){kind=link}